What is AWS S3?
3 Mart 20266 min read

People who are stepping into the cloud domain and planning to use their products on AWS often have one fundamental question in mind: “Which service can I use to store my data?”
At this point, AWS Storage, with its multiple storage types and services, can become confusing. To eliminate this confusion, let us first discuss the storage types, and then examine what AWS S3 is.
You can think of block storage as the hard disks (HDD/SSD) that we use in our personal computers. Data is divided into blocks and stored separately; the operating system then assembles these blocks to make the data meaningful.
Common use cases: Databases and disks attached to EC2 instances.
File Storage works like a shared folder. It is a system where multiple people or machines can access the same directory. It is commonly used when multiple applications or servers need to access shared files.
Now let’s move on to S3 and the concept of Object Storage. In Object Storage, data is not stored as files or blocks, but as objects. These objects can be files such as PDFs, images, or .py files. It is a storage method designed to hold independent units of data.
Object Storage does not use a traditional folder hierarchy.
It is commonly used for hosting static files (images, videos, PDFs).
It is easier to back up and more suitable for long-term storage.
It can store billions of objects.
It offers higher durability.
We can think of S3 buckets as a large warehouse, and the objects inside them as boxes stored in that warehouse. Each box inside the warehouse (S3 bucket) has a label on it, which represents the box’s ID and name. Every object placed inside a box consists of the data itself, while the information written on it represents the metadata.
The name of the S3 service comes from Simple Storage Service. It is designed to store billions of objects at a global scale. The AWS S3 service is considered the industry-standard example of object storage. It provides 11 nines (99.999999999%) of durability and strong read-after-write consistency.
Durability
Data stored in S3 is replicated across multiple devices and Availability Zones.
Thanks to this architecture, S3 provides 99.999999999% (11 nines) durability for stored data.
This means that even if you store billions of files, the probability of data loss is extremely low.
Availability
S3 provides high availability for objects, ensuring reliable access whenever they are needed.
Scalability
When using S3, there is no need to specify storage capacity in advance; S3 automatically scales as your data grows.
Performance
Objects can be accessed very quickly via internet-facing endpoints or through HTTP/HTTPS APIs from within a VPC.
In AWS S3, you can choose a different storage class for each bucket. The storage classes in S3 are designed to meet a wide range of needs. There are different bucket classes optimized for access frequency, cost, and durability requirements.
It is designed for frequently accessed files.
It provides low latency and high performance.
Durability: 99.999999999% (11 nines).
Availability: 99.99%.
It automatically tracks the access patterns of objects.
It moves objects that are not accessed for a long time to lower-cost tiers and moves them back if they are accessed again.
Advantage: Performance is the same as S3 Standard; it only provides cost optimization.
It is designed for data that is accessed infrequently but still requires fast access when needed.
The cost is lower, but there is an additional charge per access.
Durability: 99.999999999% (11 nines).
Availability: 99.9%.
It is similar to Standard-IA, but data is stored in a single Availability Zone.
It is cheaper, but data loss may occur if the Availability Zone fails.
Durability: 11 nines (single AZ).
Availability: 99.5%.
It is an ultra-low-cost storage designed for long-term archiving.
Accessing files may take a long time.
Durability: 11 nines.
Glacier has three tiers within itself:
Glacier Instant Retrieval → rarely accessed data with instant access when needed.
Glacier Flexible Retrieval → lower cost, with retrieval times ranging from minutes to hours.
Glacier Deep Archive → the lowest cost, but retrieval times range from 12 to 48 hours.
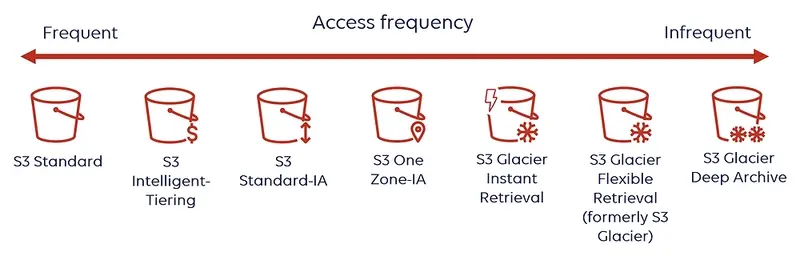 Fig.1: Enabling Amazon S3 to automatically optimize your storage costs1
Fig.1: Enabling Amazon S3 to automatically optimize your storage costs1
Under this heading, we will examine in which real-world scenarios and for which types of needs S3 is preferred, and evaluate its use cases.
Another feature of the S3 service is that it can be used for Static Website Hosting. You can store static files such as HTML, CSS, and JS in S3 and publish your static website using the static website hosting feature.
When used together with CloudFront, you can achieve a fast, secure, and globally accessible distribution! For example, a startup can publish a static promotional website via S3 and obtain a low-cost, secure, and maintenance-free solution.
A company can store database backups, application logs, or internal documents in S3 for the long term. By using Lifecycle rules to automatically move data to Glacier or Deep Archive, storage costs can be reduced.
A mid-sized company can write logs from all its applications to S3 and analyze them by running SQL queries with the Athena service. With this solution, the company can identify and address security breaches and performance issues.
A financial company can store all documents that it is legally required to retain for 7 years in S3 Glacier Deep Archive. In this way, the company can securely and cost-effectively store documents that do not require immediate access but must be retained.
In conclusion, although there are multiple storage types on AWS, Amazon S3 has become an industry standard thanks to its durability, flexible storage classes, security features, and wide range of use cases.
Whether you are a startup or a large-scale enterprise, S3 offers a solution that fits your needs. Choosing the right storage type is critical not only for cost optimization, but also for the performance and reliability of your application.
See you in the next articles 
Enabling Amazon S3 to automatically optimize your storage costs https://aws.plainenglish.io/aws-data-engineering-deep-dive-into-data-marts-and-redshift-f0da2a6a9703
Ready to simplify data storage across your AWS environment? Contact Sufle today to design the right Amazon S3 strategy and start benefiting from secure, scalable, and cost-efficient object storage.

Emir is a Cloud and Platform Engineer with extensive experience designing and operating cloud-native architectures for both fast-growing startups and enterprise-scale environments. He focuses on building secure, efficient and scalable platforms and believes that strong ownership, thoughtful architecture decision.
Check out our latest updates and articles on our usage of technology, solutions and guidances.
We use cookies to offer you a better experience.


